
MySQL下INNODB引擎的SELECT COUNT(*)性能优化及思考
最近有项目有高并发需求,服务器采用负载均衡,数据库采用阿里云的RDS MYSQL,16核64G内存,连接数:16000 IOPS:14000,前几场活动一切正常,RDS的cpu都维持在40%以内的使用率,但是后面几场的时候发现RDS的cpu达到了100%,RDS几乎挂掉了!
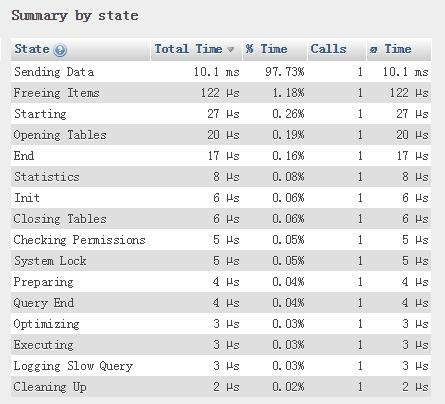
排查原因,发现了大量慢日志:
select count(*) from `roundmember`
该表的引擎原来是myisam,同样的程序在其他服务器(如腾讯云数据库)运行时并没有出现异常。检查该表,在阿里云的rds上是innodb引擎,阿里云的rds for mysql目前只支持innodb引擎,不支持myisam引擎,阿里云给出的解释是:
MyISAM引擎表不支持事务,读写操作会相互冲突,仅支持表级别锁。当其上的查询或者写入操作时间比较长的时候,会阻塞其他操作,容易导致连接堆积,而且在crash 后存在数据丢失的风险,因此RDS for MySQL推荐使用 Innodb 引擎。 目前RDS for MySQL如果导入表、新建表是MyISAM引擎或调整表引擎为MyISAM,会自动修改为Innodb引擎。
虽然从MySQL 5.5版本开始,默认引擎变成了InnoDB,但是并不代表Myisam引擎就要被淘汰,对于一些非重要数据无需事务处理而又要求高读取速度的表,飘易倒是更愿意使用myisam引擎。阿里云应该让用户自己选择,而不是代替用户选择。
话说回来,innodb引擎的表在使用select count的时候,如果表的总行数在1-2万条以内,速度应该不是瓶颈,但是一旦超过了这个值,随着行数的增多,select count查询效率会迅速的下降。
在本项目中,由于RDS性能较高,在roungmember表的总行数3万条以内的时候,select count查询速度还不错,没有成为性能瓶颈,但是超过了3万条之后,大量的慢日志就出来了,RDS CPU使用率直线飙升到100%。
此时,RDS的并发连接数在400上下,并不算太高:

本文的关键点来了,InnoDB引擎并不适合使用select count(*)查询总行数。
测试表大约4.3万行
Myisam引擎:
SELECT SQL_NO_CACHE COUNT(*) FROM `roundmember2`
耗费105微秒

innodb引擎:
耗费10335微秒
可以看出innodb引擎耗时是myisam引擎的98倍!这还是仅仅是4万多行的数据下测试的差距,随着记录行的增加,这个差距会越来越大。
MyISAM会保存表的总行数,这段代码在MyISAM存储引擎中执行,MyISAM只要简单地读出保存好的行数即可。因此,如果表中没有使用事务之类的操作,这是最好的优化方案。然而,innodb表不像myisam有个内置的计数器,InnoDB存储引擎不会保存表的具体行数,因此,在InnoDB存储引擎中执行这段代码,InnoDB要扫描一遍整个表来计算有多少行。
innodb引擎:
SELECT SQL_NO_CACHE COUNT(*) FROM `roundmember` WHERE id>0

采用where加主键id查询,耗时达到16.2ms,性能比未带id查询反而降低了。
在uid列上建立索引:
SELECT SQL_NO_CACHE COUNT(*) FROM `roundmember` WHERE uid>0

采用where加普通索引(第二索引)查询,耗时26.2ms,性能更低了。
而这样的结果似乎和网上得到的结论有一些出入:
网上的结论1:
采用 secondary index 查询要比用 primary key 查询来的快很多。那么,为什么用 secondary index 扫描反而比 primary key 扫描来的要快呢?我们就需要了解innodb的 clustered index 和 secondary index 之间的区别了。 innodb 的 clustered index 是把 primary key 以及 row data 保存在一起的,而 secondary index 则是单独存放,然后有个指针指向 primary key。因此,需要进行 count(*) 统计表记录总数时,利用 secondary index 扫描起来,显然更快。
网上的结论2:
在第一次使用了唯一索引(u_id)的时候,InnoDB使用了唯一索引作为表的聚簇索引。而在InnoDB存储引擎中,count(*)函数是先从内存中读取表中的数据到内存缓冲区,然后扫描全表获得行记录数的。因此,使用唯一索引作为聚簇索引的时候,InnoDB需要先读取110W条的数据到数据缓冲区中,这里发生了很多次I/O,因此造成了主要的时间消耗。而添加了辅助索引后,mysql在执行查询时会使用内部的优化机制:即使用辅助索引来统计数量。辅助索引保存的是index的值,此时只需要读取一个字段,I/O减少了,性能就提高了。因此在InnoDB中,如果有统计整张表的数量的需求,可以考虑增加一个辅助索引。
InnoDB Pitfalls
However, all is not rosy with InnoDB. Because of its transactional nature, it has bottlenecks of its own. On MyISAM, doing a query that does SELECT COUNT(*) FROM {some_table}, is very fast, since MyISAM keeps the information in the index.
On InnoDB, this info is not stored in an index, and even the index and the data are kept in the same file. So, doing the same query on a table can incur a significant performance penalty.
To check what overhead this has, I wrote a simple test benchmark code. I duplicated a client node table that has 20,243 rows from MyISAM to InnoDB.
On a quiescent AMD 64 machine with MySQL server 5.0.24, doing a SELECT COUNT(*) FROM node takes 0.835 milliseconds on MyISAM, while on InnoDB it takes 12.292 milliseconds!既然我们知道innodb引擎并不适合做 select count(*)查询,那么我们回过头来看看实际业务的需求是怎样的?
select count(*) from `roundmember`
采用这样的查询是因为需要查出实时参与活动的总人数,但是这里的“实时”是否一定要实时,采用准实时,用户会反感吗?或者即使有一定的偏差,普通用户能感知吗?如果我们得出答案,这个实时的参与数只要准实时,允许一定的偏差,那么就好办了:
select id from roundmember order by id desc limit 1
我们只要查最新的一条记录,id是自增字段,取当前的这个id值就可以大约知道总参与人数了(注意我们的项目里并不会删除参与记录)。
关于innodb引擎的一些知识点:
知识点一:innodb存储引擎的默认的行格式为compact(redundant为兼容以前的版本),对于blob,text,varchar(8099)这样的大字段,innodb只会存放前768字节在数据页中,而剩余的数据则会存储在溢出段中(发生溢出情况的时候适用);
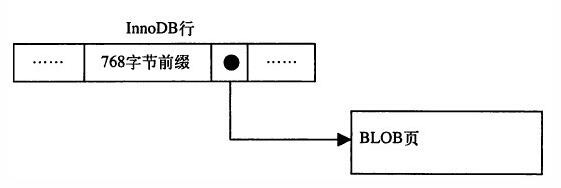
知识点二:innodb的块大小默认为16kb,由于innodb存储引擎表为索引组织表,树底层的叶子节点为一双向链表,因此每个页中至少应该有两行记录,这就决定了innodb在存储一行数据的时候不能够超过8k(8098字节);
知识点三:使用了blob数据类型,是不是一定就会存放在溢出段中?通常我们认为blob,clob这类的大对象的存储会把数据存放在数据页之外,其实不然,关键点还是要看一个page中到底能否存放两行数据,blob可以完全存放在数据页中(单行长度没有超过8098字节),而varchar类型的也有可能存放在溢出页中(单行长度超过8098字节,前768字节存放在数据页中);
知识点四:5.1中的innodb_plugin引入了新的文件格式:barracuda(将compact和redundant合称为antelope),该文件格式拥有新的两种行格式:compressed和dynamic,两种格式对blob字段采用完全溢出的方式,数据页中只存放20字节,其余的都存放在溢出段中:
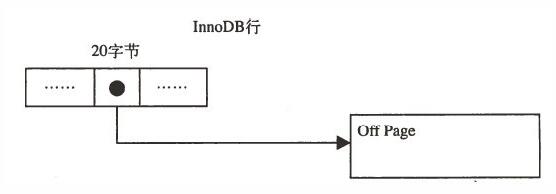
知识点五:mysql在操作数据的时候,以page为单位,不管是更新,插入,删除一行数据,都需要将那行数据所在的page读到内存中,然后在进行操作,这样就存在一个命中率的问题,如果一个page中能够相对的存放足够多的行,那么命中率就会相对高一些,性能就会有提升;
关于innodb引擎的一些优化建议:
1、每个字段的长度控制在768字节以内
原因:当Innodb的存储格式是 ROW_FORMAT=COMPACT (or ROW_FORMAT=REDUNDANT)的时候,Innodb只会存储前768字节的长度,剩余的数据存放到“溢出页”中。一旦采用了这种“溢出存储”,返回数据的时候本来是顺序读取的数据,就变成了随机读取了,会导致性能急剧下降。并且Innodb并没有将溢出页(overflow page)缓存到内存里面。
2、InnoDB 中不保存表的具体行数,也就是说,执行select count(*) from table时,InnoDB要扫描一遍整个表来计算有多少行,但是MyISAM只要简单的读出保存好的行数即可。注意的是,当count(*)语句包含 where条件时,两种表的操作有些不同,InnoDB类型的表用count(*)或者count(主键),加上where col 条件。其中col列是表的主键之外的其他具有唯一约束索引的列。这样查询时速度会很快,就是可以避免全表扫描。
3、对于AUTO_INCREMENT类型的字段,InnoDB中必须包含只有该字段的索引,但是在MyISAM表中,可以和其他字段一起建立联合索引。
4、DELETE FROM table时,InnoDB不会重新建立表,而是一行一行的删除。
5、LOAD TABLE FROM MASTER操作对InnoDB是不起作用的,解决方法是首先把InnoDB表改成MyISAM表,导入数据后再改成InnoDB表,但是对于使用的额外的InnoDB特性(例如外键)的表不适用。
6、innodb要熟练使用覆盖索引技术(建立合适的联合索引)
select a from table_name where b 这样的一个查询,都知道索引应该加在b上面,查询的处理过程:首先去检索b索引找到与其对应的索引,然后根据索引去检索正确的数据行。这样一来一去就是两次检索,能不能通过一次检索而得到数据呢?
如果希望通过一次检索得到数据,那么索引上面就应该包含其索引相对的数据,这样可能吗?
alter table_name add index (b,a);
添加一个这样的索引就能实现了, 查看是否使用了覆盖索引; 使用 explain select ...如果 extra: use index 就表示使用了覆盖索引。
【参考】:
* MySQL Sending data导致查询很慢的问题详细分析
* 在MySQL的InnoDB存储引擎中count(*)函数的优化